

Welcome to part 2 of the PicketLink Deep Dive series. In case you missed part 1, you can find it here. In part 1 you’ll also find links to helpful resources, such as the PicketLink documentation, distribution binaries, source code and more.
In this issue, we’re going to be taking a closer look at PicketLink’s support for partitions. Let’s start though by establishing what exactly partitions are in the scope of PicketLink and how they are used.
What is a Partition?
In the simplest definition, partitions in PicketLink are used to segregate identities (such as users, groups and roles) from each other. Why would you want to do this, you wonder? Well one common use case for such a feature would be for an application that serves multiple clients/companies, with each client having its own distinct set of user accounts. Another use case might be when you wish to use PicketLink as an IDP (Identity Provider) that services multiple applications, with each application having a distinct set of identities. Whenever you need to support the creation of distinct “sets” of users or other identity types, partitions are there to help you.
Do I need to use them?
If your application has simple security requirements, such as a single set of user accounts and maybe perhaps a few groups and roles, then you probably don’t need to use PicketLink’s extended support for partitions. The good news is that you don’t really need to do anything special - simply ignore the partition aspect of PicketLink and it shouldn’t ever bother you! (You can probably also skip the rest of this article if you like and just come back for part 3).
Partitions and the Identity Model
If you read part 1, you may remember how the identity model was described and how each identity object implements the IdentityType interface, as shown in this class diagram:
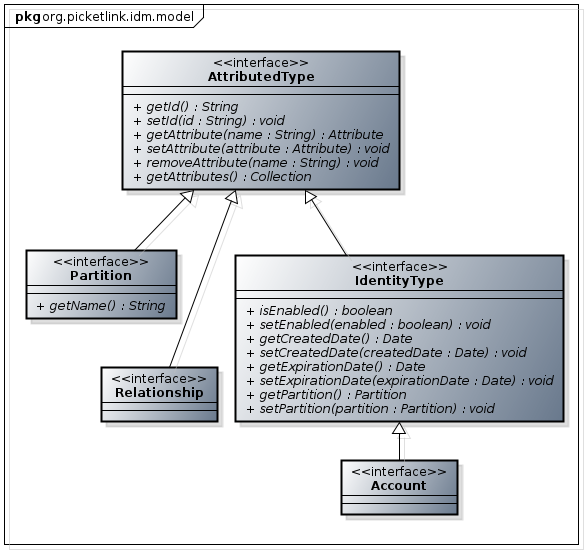
What we didn’t explain in part 1 was how every IdentityType object must belong to a Partition. This means that every user, group, role, agent, account (or any other identity type) always has a partition object, and its getPartition() method will always return this object (and never null). If you’ve worked with the PicketLink API already you may have noticed these overloaded methods on the PartitionManager interface:
IdentityManager createIdentityManager() throws IdentityManagementException;
IdentityManager createIdentityManager(Partition partition) throws IdentityManagementException;At first glance it might seem that the first of these methods might return a “partitionless” IdentityManager instance, however behind the scenes PicketLink actually returns an IdentityManager for the default partition. We’ll examine this in more detail shortly, but first let’s look at how PicketLink supports different partition types.
Creating a custom partition type
Since the Partition interface cannot be instantiated itself, it is generally up to the developer to provide a concrete partition implementation. PicketLink provides two built-in partition types which you are free to use (see the next section for details), but otherwise it is very simple to create your own partition type. The AbstractPartition abstract base class makes this easy by doing most of the work for us, and may be easily extended to create a custom partition type. Let’s take a look at a really simple example:
@IdentityPartition(supportedTypes = {IdentityType.class})
public class Organization extends AbstractPartition {
public Organization() {
super(null);
}
public Organization(String name) {
super(name);
}
}That’s all the code we need! We can use this new Organization partition type to create identities within separate Organizations. The only really significant feature worth a special mention in the above code is the @IdentityPartition annotation. This annotation tells PicketLink that the class is a partition class, and also that it allows the storing of all IdentityType types (including any subclasses of IdentityType). If we only wanted to store User objects in the partition then we could instead annotate the class like this:
@IdentityPartition(supportedTypes = {User.class})It’s also possible to “trim” support for certain identity classes off the hierarchy tree, by specifying them in the unsupportedTypes member. For example, let’s say that we wish to be able to store all identity types in an Organization, except for Roles. The annotation would now look like this:
@IdentityPartition(supportedTypes = {IdentityType.class}, unsupportedTypes = {Role.class})Finally, since the Partition interface extends AttributedType, we know that it will have a unique identifier and that we are able to also assign it arbitrary attribute values, so with our new Organization partition we can do stuff like this:
Organization org = new Organization(“acme”);
org.setAttribute(new Attribute<String>(“description”, “Manufactures anvils and other failure-prone devices”);
partitionManager.add(org);
log.info(“Created new Organization partition with id: “ + org.getId());Built In Partition Types
PicketLink provides two built-in, optional partition types - Realm and Tier. Both of these classes can be found in the org.picketlink.idm.model.basic package along with the other classes that form the basic identity model. Both of these partition types are provided for convenience only, there is absolutely no requirement that you use either of them. If you do wish to use these built-in partition types, then here are our guidelines (which you may choose to ignore if you wish):
Realm
The Realm partition type is analogous to the commonly accepted definition of a security realm and is recommended for use when you need to create a distinct set of users, groups and roles (or other identity types) for restricting access to an application. It supports all identity types.
Tier
A Tier is designed to be used in conjunction with a Realm and is intended for storing only roles or groups (or any other non-Account identity type, i.e. an identity type that isn’t capable of authenticating such as a User) while the Realm stores the Users. It is intended for storing tier-specific identities; for example if your application consists of multiple tiers, then each tier can define its own set of roles which in turn may be assigned certain tier-specific privileges. This way, a user in a separate Realm can be easily assigned one or more Tier-specific roles to give them access to the services provided by that tier.
The Default Partition
As mentioned above, Identity Management operations performed on an IdentityManager returned by the PartitionManager.createIdentityManager() method are actually done in the default partition. This default partition is actually a Realm object with a name of “DEFAULT”. If your PicketLink environment isn’t configured to support partitions then it doesn’t matter, PicketLink will transparently handle the support for the default partition without you having to do anything special.
Partitions and Relationships
So far we haven’t mentioned where identity relationships fit into the picture in regards to partitions. By their very nature, relationships differ from identities in that they don’t belong to a specific partition. If you think about this, it makes quite a lot of sense as a relationship is a typed association between two or more identities and those identities may not all exist within the same partition. For example, based on the description of the Realm and Tier partitions above we know that it is possible to have a Role that exists in a Tier, granted (via a Grant relationship) to a User in a Realm.
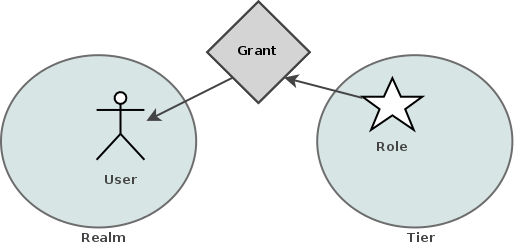
It is outside the scope of this article to go into detail about how PicketLink determines where to store relationship state, however this might be a good topic for a future deep dive.
Partitions and Multiple Configurations
PicketLink allows multiple configurations to be simultaneously declared, each with its own distinct name. A single configuration may have one or more identity stores configured for storing identity state. By supporting multiple configurations, PicketLink provides control over which backend identity store is used to store the identity state for each partition. This all might sound a little confusing, so let’s illustrate it with a diagram that describes a possible use case for a fictional paper company:
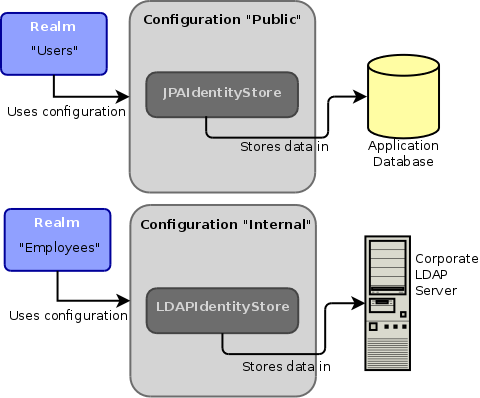
In this example our paper company has two configurations, “Public” and “Internal”. The “Public” configuration has been configured to use a JPA-based identity store which uses a database to store its identity state. The “Internal” configuration uses an LDAP-based identity store which is backed by a corporate LDAP directory. In addition to these two configurations, we also have two realm partitions - “Users” and “Employees”.
Let’s also assume that our paper company runs an ecommerce web site where anyone can log in and place an order for their products. The login page for public users might look something like this:
When logging in through this login form (which is easily found via a “Sign In” link on the main page of the site), authentication will be performed using the “Users” realm. The site may also provide an employee portal for managing orders and possibly performing other back-office tasks. Employees wishing to access this portal would use a different web address (or maybe an entirely different application, possibly even available only on the company private network) and would authenticate with an “employee-only” login form backed by the “Employees” realm. We can represent the distinct login pages and their associated realms using the following diagram:
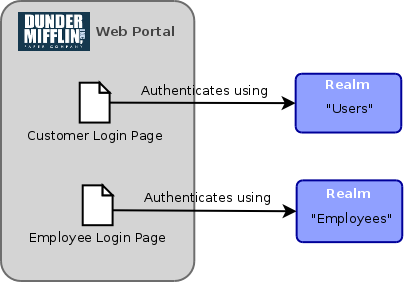
An application may be modelled to support this multi-faceted application in a number of ways; it may be structured as a number of separate Tiers, with each tier providing a limited set of functions (possibly implemented as separate applications and/or services) and a set of tier-specific roles to control how privileges to access those functions are assigned; it could also be structured as a single monolithic application that “does everything” (™), restricting access to certain areas depending on the access level of the current user. In either case, application-wide privileges can be easily assigned to individual users from either realm. For example, if the privilege takes the form of a role or group membership, it’s possible for that role or group to exist in one realm and a user to which it is assigned exist in another realm.
Let’s say for example that an “admin” role for our paper company’s web portal is defined in the “Users” realm, and that this role is required to access the “Review Orders” page of the site:
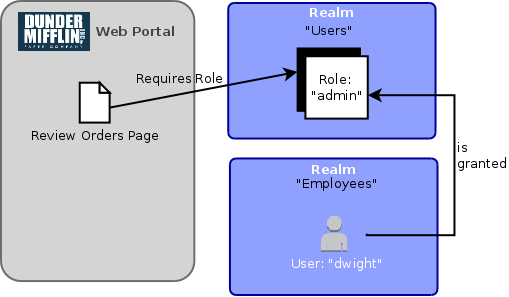
As we can see, it doesn’t matter that the user to which this role is assigned exists in a different realm, because as we mentioned previously, relationships by their very nature are “cross-partitioned” and so can be used to assign privileges between distinct realms.
Partition Management API
PicketLink provides a simple PartitionManager API for managing partitions. It can be easily injected into your application like so:
import org.picketlink.idm.PartitionManager;
import javax.inject.Inject;
public class AdminService {
@Inject PartitionManager partitionManager;
}Once you have the PartitionManager instance, you can retrieve an existing Partition like so:
Realm default = partitionManager.<Realm>getPartition(Realm.class, “default”);Or you can retrieve all partitions of a certain type:
List<Realm> realms = partitionManager.<Realm>getPartitions(Realm.class);Creating a new Partition is also simple:
Tier orderServices = new Tier(“orderServices”);
partitionManager.add(orderServices);As is removing a Partition:
Realm tempUsers = partitionManager.<Realm>getPartition(Realm.class, “temp”);
partitionManager.remove(tempUsers);To create users and other identity objects within a Partition, get a reference to its IdentityManager via the createIdentityManager() method:
Realm default = partitionManager.<Realm>getPartition(Realm.class, “default”);
IdentityManager im = partitionManager.createIdentityManager(default);
User jsmith = new User(“jsmith”);
im.add(jsmith);To grant permissions to users within a Partition, get a reference to its PermissionManager via the createPermissionManager() method:
Realm default = partitionManager.<Realm>getPartition(Realm.class, “default”);
User jsmith = new User(“jsmith”);
im.add(jsmith);
PermissionManager pm = partitionManager.createPermissionManager(default);
pm.grantPermission(jsmith, Order.class, “CREATE”);To create relationships, get a reference to a partitionless RelationshipManager via the createRelationshipManager():
RelationshipManager rm = partitionManager.createRelationshipManager();Once you have the RelationshipManager you can use it to create relationships either between identities in the same partition, like so:
Realm default = partitionManager.<Realm>getPartition(Realm.class, “default”);
IdentityManager im = partitionManager.createIdentityManager(default);
User jsmith = new User(“jsmith”);
im.add(jsmith);
Role admin = new Role(“admin”);
im.add(admin);
rm.add(new Grant(jsmith, admin));Or between relationships in different partitions:
Realm default = partitionManager.<Realm>getPartition(Realm.class, “default”);
IdentityManager im = partitionManager.createIdentityManager(default);
User jsmith = new User(“jsmith”);
im.add(jsmith);
Tier serviceTier = partitionManager.<Tier>getPartition(Tier.class, “service”);
IdentityManager tim = partitionManager.createIdentityManager(serviceTier);
Role admin = new Role(“admin”);
tim.add(admin);
rm.add(new Grant(jsmith, admin));Summary
PicketLink’s advanced support for partitions allows us to create security architectures suitable for simple, single-purpose applications ranging through to complex, multi-tier enterprise platforms. In this article we examined how partitions can be used to create distinct sets of identities, and we explored how to manage partitions using the PartitionManager API.
Once again, thanks for reading!
