
Cross-posted from Substack.
Jakarta Data is a new specification for persistence in Java, scheduled for release as part of the EE 11 platform. Whereas Jakarta Persistence provides a mature and extremely feature-rich foundation for object/relational mapping solutions like Hibernate, Jakarta Data aims to offer a somewhat simplified programming model, but one which is also suitable for use with non-relational databases.
The concept of a “repository”
Jakarta Data is a programming model for repositories. Early versions of the specification featured what I’ve taken to calling “DAO-style” repositories, along the lines of established solutions like Spring Data. In this approach, each entity has its own repository interface offering persistence operations dedicated to that particular entity. So for Book, there’s a BookRepository, for Author, there’s an AuthorRepository, and so on.
Folks who follow me on Twitter know I’ve long been a skeptic of this approach. I don’t want to revisit all the arguments here, but let me quickly touch on the following points, since they helped motivate the (new) design of Jakarta Data:
-
For relational data the division of operations by entity is unnatural. Most interesting queries operate across multiple entities, and very often across entities which—just like my favorite
Book/Authorexample—participate in many-to-many associations. It’s unnatural to assign such operations to one entity. Please note that this point is specific to relational data. For a document database, DAO-style repositories are completely natural. I really don’t want to go too far down this rabbit hole here, but let me just bait you with the thought that this is an under-appreciated aspect of the O/R mapping problem, and an aspect which one particular section of the community has completely missed. -
In a typical mature system, there are many more queries than entities, and this leads to a DAO filling up with many operations with extremely low cohesion.
-
Older frameworks offered little-to-no additional type safety, only extremely modest reductions in code (at best), and interposed a whole extra layer of framework code between the application program and the database, while making it more difficult to get access to advanced and performance-related features of Hibernate.
-
Older implementations based on JPA offered a CRUD-style API which was a completely inappropriate abstraction of JPA’s stateful persistence context. In a stateful persistence context, updates are implicit, so an
update()method makes no sense.
In light of all this, Jakarta Data provides repositories which are not tied to one particular entity. Instead, persistence operations may be categorized according whatever classification you as a software designer dream up. Instead of BookRepository and AuthorRepository you might have Bookstore and Library. Indeed, the idea is that you could have many fine-grained repository interfaces, with operations classified by client or by topic, each with much improved cohesion, each operating over multiple entities.
But this isn’t what changed my mind about repositories, and it’s not really enough reason for you to start using them instead of just calling EntityManager. What made all the difference for me was realizing the potential for much greater type safety, a potential that older frameworks have simply failed to properly exploit. This realization grew out of work I began as part of Hibernate 6.3, but it reaches its apotheosis in the Jakarta Data specification. But now we’re getting ahead of ourselves.
Getting started with Jakarta Data on Hibernate
Enough with the handwaving. If you want to try out Jakarta Data today, you’ll need the M4 release, and you’ll need a snapshot build of Hibernate 6.6:
-
here’s a Gradle build you could use, or
-
if you want to try it out in Quarkus, check out this Maven POM.
Notice that it’s essential to enable HibernateProcessor, the annotation processor in the now inappropriately-named hibernate-jpamodelgen module. The annotation processor contains Hibernate’s implementation of Jakarta Data.
If you’re wondering why we implemented Jakarta Data using an annotation processor, instead of using reflection, or bytecode generation, or some other such runtime technique, the answer is type safety. HibernateProcessor is able to detect an incredible array of different kinds of error at compile time, and reports such problems with easily-understandable messages, as we’ll see later. This compile-time error reporting is the main reason to use Jakarta Data with Hibernate.
Of course, we’ll need some JPA entity classes:
@Entity
public class Book {
@Id
String isbn;
@Basic(optional = false)
String title;
LocalDate publicationDate;
@Basic(optional = false)
String text;
@Enumerated(STRING)
@Basic(optional = false)
Type type = Type.Book;
@ManyToOne(optional = false, fetch = LAZY)
Publisher publisher;
@ManyToMany(mappedBy = Author_.BOOKS)
Set<Author> authors;
...
}
@Entity
public class Author {
@Id
String ssn;
@Basic(optional = false)
String name;
Address address;
@ManyToMany
Set<Book> books;
}Jakarta Data also works with entities defined using Jakarta NoSQL annotations, but here we’re using Hibernate ORM, so these annotations are the ones you already know from jakarta.persistence. There’s nothing new here.
Next, let’s create our first repository, calling it Library, just for fun:
@Repository
public interface Library {}The @Repository annotation tells HibernateProcessor to generate an implementation of this interface. When we compile our code, we obtain the following generated class:
@RequestScoped
@Generated("org.hibernate.processor.HibernateProcessor")
public class Library_ implements Library {
protected @Nonnull StatelessSession session;
public Library_(@Nonnull StatelessSession session) {
this.session = session;
}
public @Nonnull StatelessSession session() {
return session;
}
@PersistenceUnit
private EntityManagerFactory sessionFactory;
@PostConstruct
private void openSession() {
session = sessionFactory.unwrap(SessionFactory.class).openStatelessSession();
}
@PreDestroy
private void closeSession() {
session.close();
}
@Inject
Library_() {
}
}As you can see, this is an injectable CDI bean, which makes use of a Hibernate StatelessSession to interact with the database. You may obtain an instance from CDI using:
@Inject Library library;On the other hand, if you don’t have CDI available in your environment, no problem, HibernateProcessor will generate simpler code without any dependence on CDI. And you always have the option to instantiate the repository using new:
Library library = new Library_(sessionFactory.openStatelessSession());If we need to get direct access to the StatelessSession underling Library, we can just add a method like this:
@Repository
public interface Library {
StatelessSession session();
}This method is especially useful when our repository interface has default methods we’re going to implement by hand.
I should mention that Library_ wasn’t the only class generated when we compiled our code. We also obtained:
-
Jakarta Persistence static metamodel classes
Author_andBook_, along with -
Jakarta Data static metamodel classes
_Authorand_Book.
Let’s hope the Jakarta platform never needs to introduce a third persistence API, because we’ve just run out of locations we can put an underscore.
So far, our repository doesn’t have any useful operations.
Lifecycle methods
A lifecycle method is indicated by an annotation. In Jakarta Data 1.0, there are four lifecycle annotations, and the first three have names matching the operations of StatelessSession:
@Repository
public interface Library {
@Insert
void addToCollection(Book book);
@Delete
void removeFromCollection(Book book);
@Insert
void newAuthor(Author author);
@Update
void updateAuthor(Author author);
}Compiling this code produces implementations in Library_, including the following method:
@Override
public void addToCollection(Book book) {
if (book == null) throw new IllegalArgumentException("Null book");
try {
session.insert(book);
}
catch (EntityExistsException exception) {
throw new jakarta.data.ex.EntityExistsException(exception);
}
catch (PersistenceException exception) {
throw new DataException(exception);
}
}I think you’ll agree that this code is easy to understand and debug.
I said there were four lifecycle annotations in Jakarta Data 1.0, but I’ve only shown you three of them. Here’s the fourth:
@Save
void addOrUpdate(Book book);Now, “save” here has absolutely nothing to do with a legacy (and deprecated) method with a similar name on Hibernate’s Session interface. It actually results in a SQL merge statement.
Here’s the generated implementation.
@Override
public void addOrUpdate(Book book) {
if (book == null) throw new IllegalArgumentException("Null book");
try {
session.upsert(book);
}
catch (OptimisticLockException exception) {
throw new OptimisticLockingFailureException(exception);
}
catch (PersistenceException exception) {
throw new DataException(exception);
}
}That’s right, @Save maps to upsert(). Nice, huh?
Well, now it’s time to break the bad news, at least if you’re a fan of JPA-style stateful persistence contexts. You might already be yelling at the screen wanting to know why there’s no @Persist, @Merge, @Refresh, @Lock, and @Remove annotations mapping to the standard operations of a JPA EntityManager. The answer is simply that they’re not in Jakarta Data 1.0, but they’re almost certainly coming later. Repositories in Jakarta Data are stateless, at least for now.
|
An astute observer will have already noticed that Jakarta Data lifecycle methods offer no advantage compared to just calling the equivalent methods of StatelessSession directly. But that’s because lifecycle methods are boring. What we really care about are queries.
Automatic query methods
An automatic query method is the simplest method ever devised to express a query for an entity. The parameters of the method express the query conditions. Let’s consider the simplest possible example:
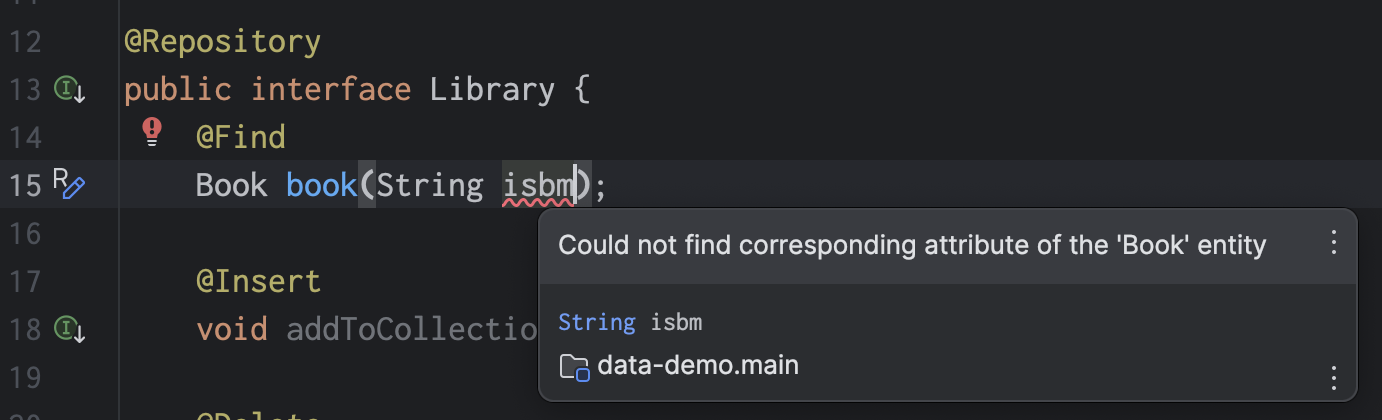
@Find
Book book(String isbn);That’s it, that’s the query.
This query retrieves the Book with the given isbn. Jakarta Data uses the name of the method parameter to identify the field we’re using to restrict the query results.
At this point, you’re sure I’m lying to you, and that there’s no way this ridiculous “query” is type safe. But you’re wrong:
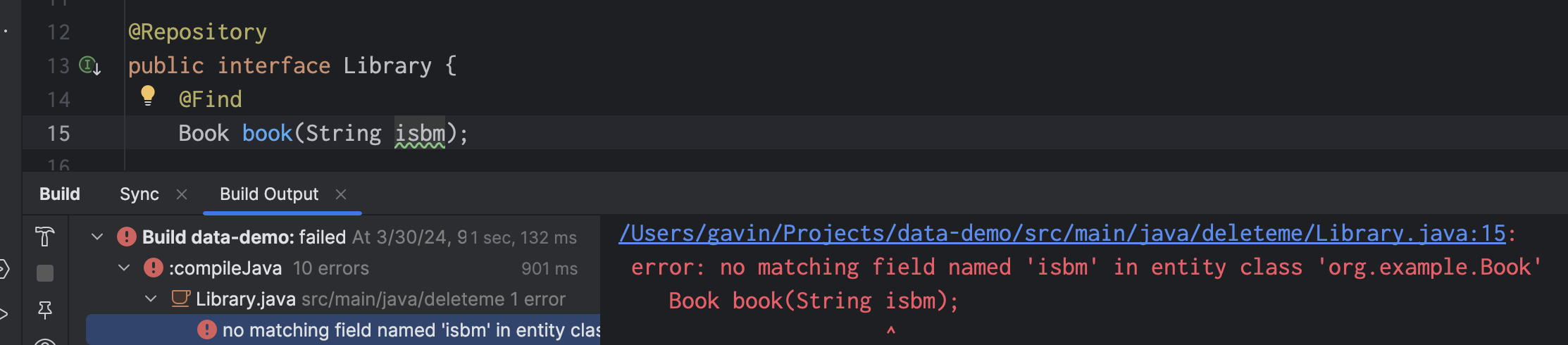
This is better than whatever DAO-style repository framework you’re using today, and it’s not even close. Quite soon, IntelliJ itself will report these errors as you’re typing, without even needing to call the annotation processor.
Automatic queries can get quite a lot more interesting. This one is sort of medium-level interesting:
@Find
List<Book> booksByTitle(@Pattern String title, Type type,
Order<Book> order, Limit limit);We’re not going any further down this path today, because I have something even better to tell you about. I should, however, show you the generated code for the methods we’ve just seen.
For our first example, HibernateProcessor recognized that isbn is the primary key of Book, and generated this code:
@Override
public Book book(String isbn) {
if (isbn == null) throw new IllegalArgumentException("Null isbn");
try {
return session.get(Book.class, isbn);
}
catch (NoResultException exception) {
throw new EmptyResultException(exception);
}
catch (NonUniqueResultException exception) {
throw new jakarta.data.ex.NonUniqueResultException(exception);
}
catch (PersistenceException exception) {
throw new DataException(exception);
}
}For the second “medium interesting” example, we obtain:
@Override
public List<Book> booksByTitle(String title, Type type, Order<Book> order, Limit limit) {
if (type == null) throw new IllegalArgumentException("Null type");
var _builder = session.getFactory().getCriteriaBuilder();
var _query = _builder.createQuery(Book.class);
var _entity = _query.from(Book.class);
_query.where(
title==null
? _entity.get(Book_.title).isNull()
: _builder.like(_entity.get(Book_.title), title),
_builder.equal(_entity.get(Book_.type), type)
);
var _orders = new ArrayList<Order<? super Book>>();
for (var _sort : order.sorts()) {
_orders.add(by(Book.class, _sort.property(),
_sort.isAscending() ? ASCENDING : DESCENDING,
_sort.ignoreCase()));
}
try {
return session.createSelectionQuery(_query)
.setFirstResult((int) limit.startAt() - 1)
.setMaxResults(limit.maxResults())
.setOrder(_orders)
.getResultList();
}
catch (PersistenceException exception) {
throw new DataException(exception);
}
}This might appear a little scary at first glance, but if you know the JPA CriteriaQuery API, you’ll quickly make sense of it. Notice that even the generated implementation of this method is completely statically type safe.
Annotated query methods
An annotated query method is one where the query is expressed in a language like Jakarta Data Query Language (JDQL), Jakarta Persistence Query Language (JPQL), or native SQL. JDQL is a strict subset of JPQL, and so Hibernate supports all three of these options.
The @Query annotation lets us specify a query written in JDQL or JPQL:
@Query("select b " +
"from Book b join b.authors a " +
"where a.name = :authorName " +
"order by a.ssn, b.isbn")
List<Book> booksBy(String authorName);Alright, so this time you’ve got me for sure. There’s no way that horrible string is type safe! Everyone here knows how queries embedded in Java strings work.
Wrong again:

Yes, that’s right: HibernateProcessor not only syntax-checks your query at compile time, it also type-checks the whole query! Some pretty sophisticated machinery underlies this, machinery it’s taken us years to build.
But the folks at JetBrains also have some pretty sweet machinery, and IntelliJ will also be able to do it very soon:
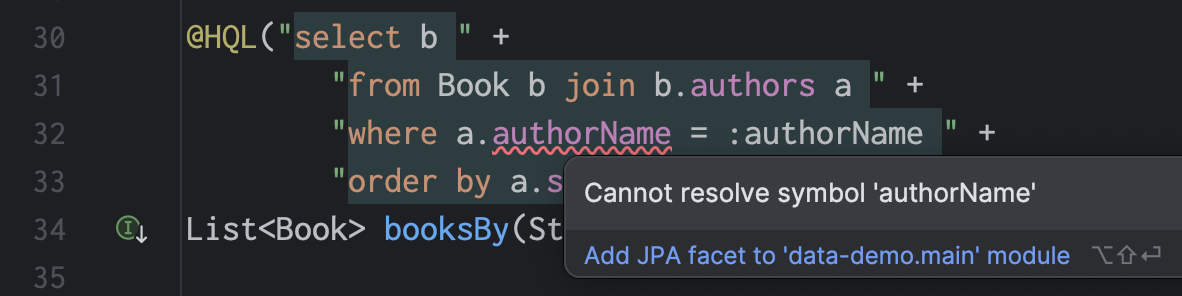
To achieve greater type safety, people sometimes advocate the use of convoluted, barely-readable internal DSLs like CriteriaQuery (which I had a hand in designing, so please don’t take offense at those adjectives), or JOOQ, or whatever. I now consider this approach obsolete. JPQL is far more readable than criteria queries.
Now, sure, an internal DSL is still nice when we really need to build a query dynamically. (Future versions of Jakarta Data will have a nice way to partially address that problem too!) So CriteriaQuery ain’t dead quite yet.
Oh, right, before I forget: the generated code. By now you can probably guess it:
@Override
public List<Book> booksBy(String authorName) {
try {
return session.createSelectionQuery(BOOKS_BY_String, Book.class)
.setParameter("authorName", authorName)
.getResultList();
}
catch (PersistenceException exception) {
throw new DataException(exception);
}
}Of course, there’s much more I could say about JDQL and about query methods in general. A particularly interesting topic—which I’ll leave for a future post—is offset-based and key-based (or “keyset”) pagination.
Current status
Jakarta Data 1.0 and Jakarta Persistence 3.2 are now very close to release, and they’re the biggest news in Java persistence in more than a decade. We’re already in the process of wrapping up our implementation of Persistence 3.2 in Hibernate 7.0. Our implementation of Jakarta Data has been done on the Hibernate 6 branch, and will be available first in 6.5 or 6.6.
Continue reading Part II.
